Introduction
Decision tree learning is a method for assessing the most likely outcome value by taking into account the known values of the stored data instances. This learning method is among the most popular of inductive inference algorithms and has been successfully applied in broad range of tasks such as assessing the credit risk of applicants and improving loyality of regular customers.
Information, Entropy and Information Gain
There are several software tools already available which implement various algorithms for constructing decision trees which optimally fit the input dataset. Nevertheless it is useful to clarify the underlying principle.
Information
First let's briefly discuss the concept of information. In simplified form we could say that the information is a measure of uncertainty or surprise; the more we are surprised about the news the bigger is the information. If there was a newspaper which pubblished a news about the morning sunrise certainly none of the readers would be interested in such story because it doesn't hold any information - the sunrise is a fact and we know it will happen tomorrow again. On the other hand if a story in a newspaper is about something noone expected it's a big news. An example is Michael Jackson's death. It happened during the time of one of the worst recessions which affected the whole world but according to the statistics the news about Michael Jackson were far more interesting than the economic facts of the time.
EntropyIn General entropy is the measure of the uncertainty associated with random variable. In case of stored instances entropy is the measure of the uncertainty associated with the selected attribute.
 where
where 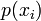 is the probability mass function of outcome
is the probability mass function of outcome  .
.Information Gain
Information gain is the expected reduction in entropy caused by partitioning the examples according to the attribute. In machine learning this concept can be used to define a preferred sequence of attributes to investigate to most rapidly narrow down the state of the selected attribute. Such a sequence (which depends on the outcome of the investigation of previous attributes at each stage) forms a decision tree. Usually an attribute with high information gain should be preferred to other attributes.

An Example
The process of decision tree construction is described by the following example: There are 14 instances stored in the database described with 6 attributes: day, outlook, temperature, humidity, wind and playTennis. Each instance describes the facts of the day and the action of the observed person (played or not played tennis). Based on the given record we can assess which factors affected the person's decision about playing tennis.
 For the root element an attribute with the highest entropy is selected. In the case of this example it is the outlook because it is the most uncertain parameter.
For the root element an attribute with the highest entropy is selected. In the case of this example it is the outlook because it is the most uncertain parameter.After the root parameter is selected the information gain for every possible combination of pair is calculated and then the branches are selected upon the information gain value; the higher is the information gain the more reliable the branch is.
 Entropy(S) is the entropy of classificator PlayTennis - there are 14 instances stored in the dataset from which a person decides do play tennis 9 times (9+) and not to play 5 times (5-).
Entropy(S) is the entropy of classificator PlayTennis - there are 14 instances stored in the dataset from which a person decides do play tennis 9 times (9+) and not to play 5 times (5-).
 The above example shows the calculation of the information gain value of classificator Wind: There are 8 instances of value Weak. In case of weak wind a person decides to play tennis 6 times and not to play 2 times [6+, 2-]. In case of strong wind (6 instances) the user decides to play 3 times and not to play 3 times as well. Considering the given instances the calculated value of information gain of attribute wind is 0.48.
The above example shows the calculation of the information gain value of classificator Wind: There are 8 instances of value Weak. In case of weak wind a person decides to play tennis 6 times and not to play 2 times [6+, 2-]. In case of strong wind (6 instances) the user decides to play 3 times and not to play 3 times as well. Considering the given instances the calculated value of information gain of attribute wind is 0.48.Information gain values of all attributes are calculated in the same way and the results are the following:
Gain(S, Outlook) = 0.246
Gain(S, Humidity) = 0.151
Gain(S, Wind) = 0.048
Gain(S, Temperature) = 0.029
Using WEKA
The example is taken from the Book Data Mining: Practical Machine Learning Tools and Techniques, Second Edition (Morgan Kaufmann Series in Data Management Systems)
The .arff file
One of possible options for importing the record in WEKA tool is writing records in .arff file format. In this example the file looks like the following:
@relation PlayTennis
@attribute day numeric
@attribute outlook {Sunny, Overcast, Rain}
@attribute temperature {Hot, Mild, Cool}
@attribute humidity {High, Normal}
@attribute wind {Weak, Strong}
@attribute playTennis {Yes, No}
@data
1,Sunny,Hot,High,Weak,No,?
2,Sunny,Hot,High,Strong,No,?
3,Overcast,Hot,High,Weak,Yes,?
4,Rain,Mild,High,Weak,Yes,?
5,Rain,Cool,Normal,Weak,Yes,?
6,Rain,Cool,Normal,Strong,No,?
7,Overcast,Cool,Normal,Strong,Yes,?
8,Sunny,Mild,High,Weak,No,?
9,Sunny,Cool,Normal,Weak,Yes,?
10,Rain,Mild,Normal,Weak,Yes,?
11,Sunny,Mild,Normal,Strong,Yes,?
12,Overcast,Mild,High,Strong,Yes,?
13,Overcast,Hot,Normal,Weak,Yes,?
14,Rain,Mild,High,Strong,No,?
The file can then be imported using WEKA explorer. When the above file is imported the interface looks like the following:
 Figure: Available attributes (left) and graphical representation (right) from the file data
Figure: Available attributes (left) and graphical representation (right) from the file dataafter the data is imported there is a set of classification methods available under the classification tab. In this case the c4.5 algorithm has been chosen which is entitled as j48 in Java and can be selected by clicking the button choose and select trees->j48.

The tree is then created by selecting start and can be displayed by selecting the output from the result list with the right-mouse button choosing the option "Visualize Tree".
 Figure: The decision tree constructed by using the implemented C4.5 algorithm
Figure: The decision tree constructed by using the implemented C4.5 algorithmThe algorithm implemented in WEKA constructs the tree which is consistent with the information gain values calculated above: the attribute Outlook has the highest information gain thus it is the root attribute. Attributes Humidity and Wind have lower information gain than Outlook and higher than Temperature and thus are placed below Outlook. The information gain of a specific branch can be calculated the same way as the example above. For example if we were interested what is the information gain of branch (Outlook, Temperature) the attributes Outlook and Temperature should be placed in the equation for calculating the information gain.
References
Data Mining and KnowledgeDiscovery; Prof. Dr. Nada Lavrač
Data Mining: Practical Machine Learning Tools and Techniques, Second Edition; Ian H. Witten, Eibe Frank


